18 Apr 2020 •
MANAGEMENT
CULTURE
PRODUCT
The purpose of an engineering organization (at the risk of sounding frivolously reductionist) is to build business value. You can grow an organization’s delivered business value over time by:
- training members: investing in people,
- improving process: investing in shaping behaviour and communication,
- staking technical leverage: investing in technology.
A cumulative side-effect of these approaches is to strengthen innovation loops.
Innovation Loops
Innovation loops are informal, intrapreneurial feedback loops in engineering teams which builds products & features to address user demand & pain. It is innovation which circumvents the software development cycle involving product & market research teams. In mature teams, innovation loops complement & reinforce the existing, evolutionary product development feedback cycle. I call product development evolutionary, in contrast to the more revolutionary (or reactive) trait of innovation loops.
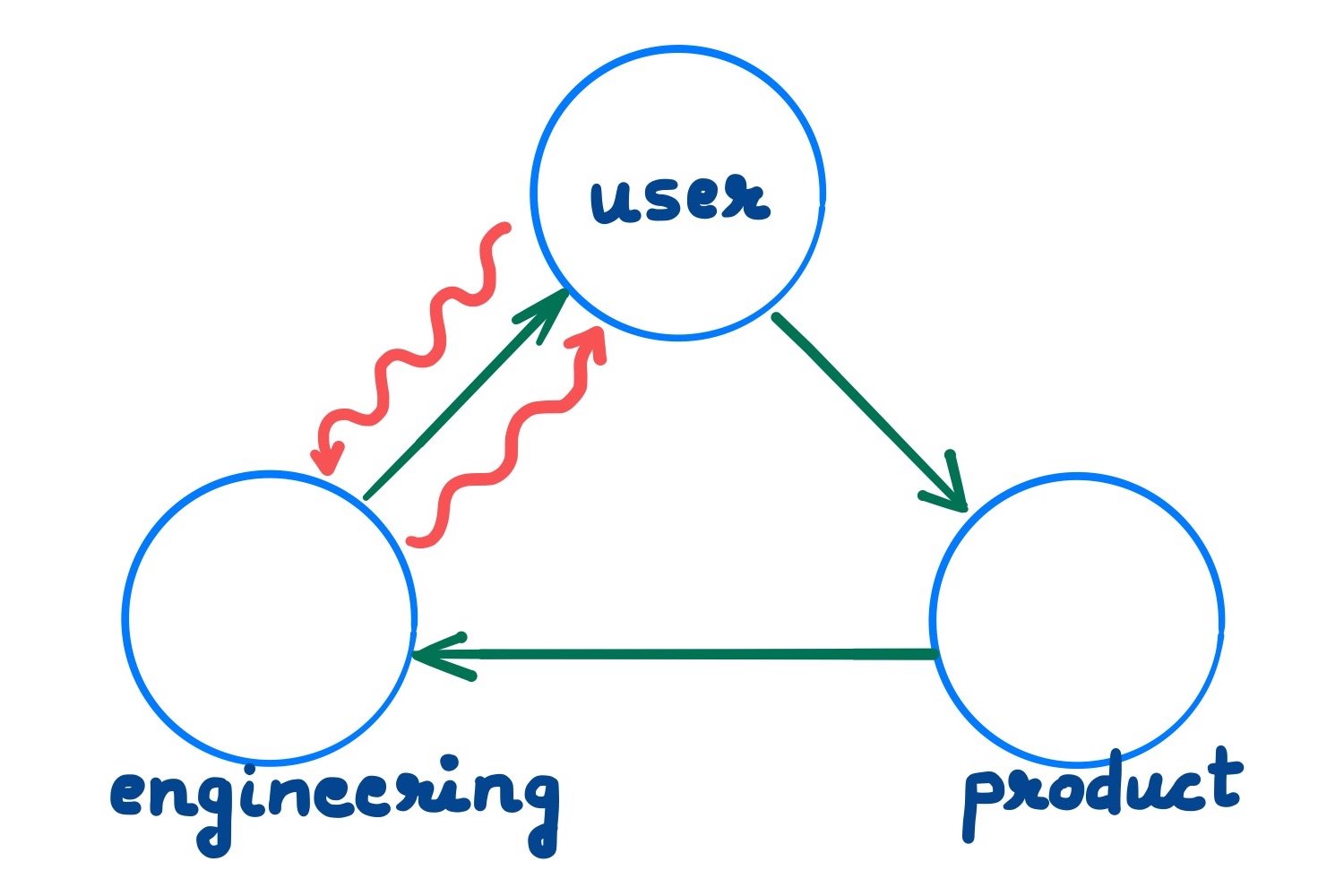
Regular product development as green arrows; Innovation loops as red squiggles.
Innovation loops are more prevalent in infrastructure teams than in product-focused teams. This could be partly explained by the availability of direct communication channels to users which infrastructure teams possess, and product-focused teams do not.
.. Read More
25 Mar 2020 •
APACHE-SPARK
A recent exercise I undertook of upgrading Apache Spark for some workloads from v2.4.3 to v2.4.5 surfaced a number of run-time errors of the form:
org.apache.spark.sql.AnalysisException: Cannot resolve column name "name" among (id, place);
at org.apache.spark.sql.Dataset$$anonfun$resolve$1.apply(Dataset.scala:223)
at org.apache.spark.sql.Dataset$$anonfun$resolve$1.apply(Dataset.scala:223)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.Dataset.resolve(Dataset.scala:222)
at org.apache.spark.sql.Dataset.col(Dataset.scala:1274)
at org.apache.spark.sql.DataFrameNaFunctions$$anonfun$toAttributes$2.apply(DataFrameNaFunctions.scala:475)
A little poking-around showed this error occurred for transformations with a similar general shape. The following is a minimal example to recreate it:
val df = Seq(
("1", "Berlin"),
("2", "Bombay")
).toDF("id", "place")
df.na.fill("empty",Seq("id", "place", "name"))
This looks wrong, but apparently works fine in v2.4.3 😲. A transformation which attempts to fill in a missing value for a column which does not exist should raise an error: v2.4.5 does that.
.. Read More
21 Feb 2020 •
CONVERSATIONS
DATA-SYSTEMS

I was recently on the Software Engineering Daily podcast to talk about Data Engineering at Nubank.
It turned to be a great conversation on functional data engineering, the importance of testability & reproducibility in data engineering (and our approach to achieving it at scale at Nubank), thinking of dataset quality in terms of dataset-as-a-service, and my take on the history of data engineering as a rediscovery of the table abstraction. Check it out here.
24 Nov 2019 •
MESOS
DATA-SYSTEMS
PAPER-SUMMARY
 Mesos is a framework I have had recent acquaintance with. We use it to manage resources for our Spark workloads. The other resource management framework for Spark I have prior experience with is Hadoop YARN. In this article, I revisit the concept of cluster resource-management in general, and explain higher-level Mesos abstractions & concepts. To this end, I borrow heavily the classification of cluster resource-management systems from the Omega paper.
Mesos is a framework I have had recent acquaintance with. We use it to manage resources for our Spark workloads. The other resource management framework for Spark I have prior experience with is Hadoop YARN. In this article, I revisit the concept of cluster resource-management in general, and explain higher-level Mesos abstractions & concepts. To this end, I borrow heavily the classification of cluster resource-management systems from the Omega paper.
The Omega system is considered one of the precusors to Kubernetes. There is a fine article in ACM Queue describing this history. Also, Brian Grant has some rare insights into the evolution of cluster managers in Google from Omega to Kubernetes in multiple tweet-storms, such as this and this.
.. Read More