Mesos, in the light of Omega
24 Nov 2019 •MESOS DATA-SYSTEMS PAPER-SUMMARY  Mesos is a framework I have had recent acquaintance with. We use it to manage resources for our Spark workloads. The other resource management framework for Spark I have prior experience with is Hadoop YARN. In this article, I revisit the concept of cluster resource-management in general, and explain higher-level Mesos abstractions & concepts. To this end, I borrow heavily the classification of cluster resource-management systems from the Omega paper.
Mesos is a framework I have had recent acquaintance with. We use it to manage resources for our Spark workloads. The other resource management framework for Spark I have prior experience with is Hadoop YARN. In this article, I revisit the concept of cluster resource-management in general, and explain higher-level Mesos abstractions & concepts. To this end, I borrow heavily the classification of cluster resource-management systems from the Omega paper.
The Omega system is considered one of the precusors to Kubernetes. There is a fine article in ACM Queue describing this history. Also, Brian Grant has some rare insights into the evolution of cluster managers in Google from Omega to Kubernetes in multiple tweet-storms, such as this and this.
Overview
I would like to start by defining the anatomy of distributed systems’ Mesos caters to.
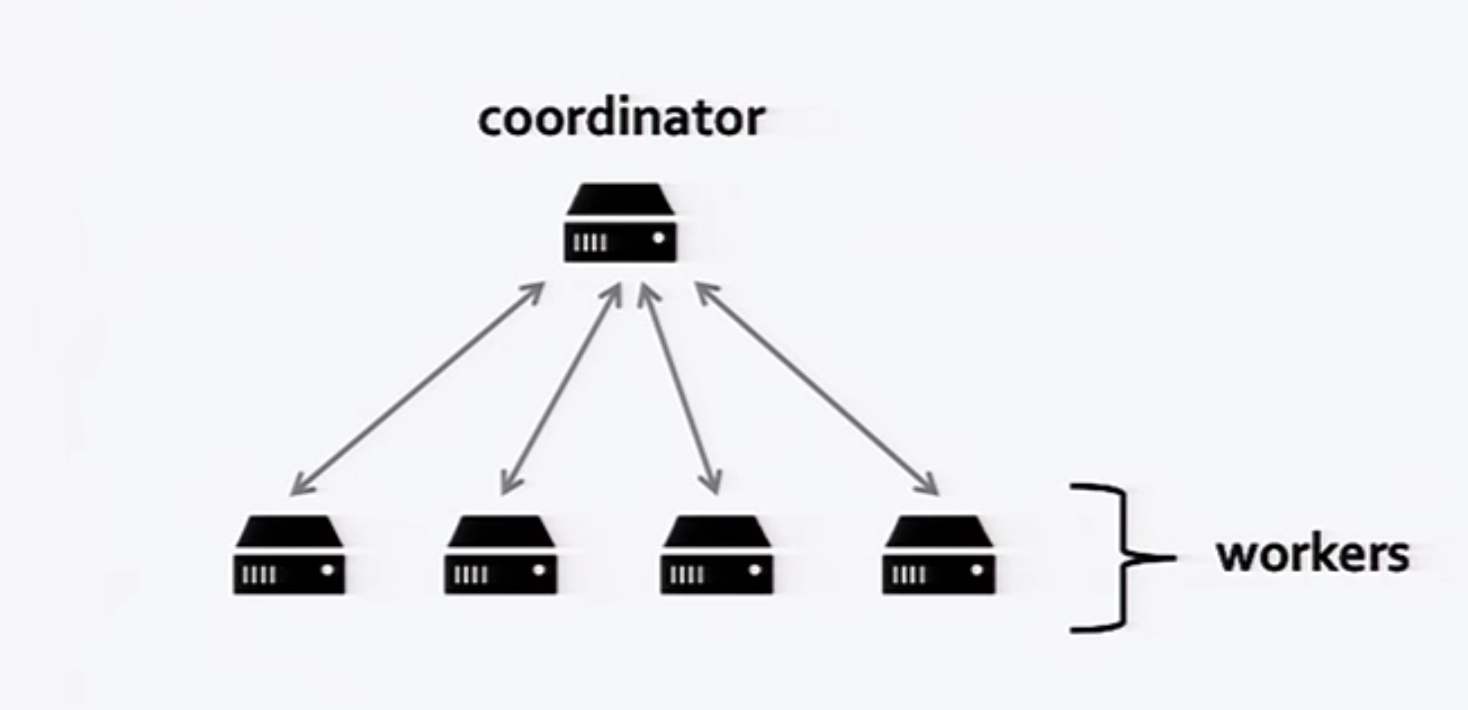
This class of distributed systems have one (or multiple) co-ordinator(s)1 co-ordinating the execution of a program across a bunch of workers distributed within a cluster of machines. The co-ordinators have a set of desirable properties:
- Distributed
- Fault-tolerant
- Elastic
Distributed refers to the simultaneous execution of program tasks2 across multiple machines. This is nothing short of what is expected from a distributed system.
Fault-tolerance is the capability of the system to handle failures of a subset of workers in the cluster, and the ability to reschedule tasks away from those failing workers.
Elasticity is the capability of the system to optimise performance and resource utilisation in a cluster, given simultaneous workloads competing for resources. It could be considered the defining characteristic which differentiates cluster resource-management paradigms & systems; say, Mesos from YARN, or Kubernetes. The next section explores elasticity in some depth.
Elasticity
An elastic system is able to adapt to workload changes by provisioning and de-provisioning resources in an autonomic manner, such that at each point in time the available resources match the current demand as closely as possible. 3
Elasticity, as defined above, is a scheduling problem. There are multiple design choices to consider to achieve elasticity and based on these choices, resource-management systems can be bucketed into categories. The table below lists the categories suggested in the paper, along with the design choices:
| Approach | Resource Choice | Interference | Allocation Granularity | Fairness |
|---|---|---|---|---|
Monolithic |
All Available | None (Serialized) | Global Policy | Strict Priority (Preemption) |
Statically Partitioned |
Fixed Subset | None (Partitioned) | Per-partition Policy | Scheduler-dependent |
Two-Level [Mesos] |
Dynamic Subset | Pessimistic | Hoarding | Strict Fairness (Dominant Resource Fairness) |
Shared-State [Omega] |
All Available | Optimistic | Per-scheduler Policy | Free-for-all, Priority Preemption |
The design choices can be described briefly as follows:
- Choice of Resources to Participating Workloads
- Do participating workloads (effectively, schedulers of participating workloads) have a universal view of cluster state and universal access to cluster resources? Or is it a limited view and restricted access?
- Preemptive scheduling vs. Non-preemptive scheduling.
- Interference
- Pessimistic approach to resource sharing, vs. Optimistic concurrency with conflict resolution.
- Allocation Granularity
- Gang-scheduling vs. Incremental allocation.
- Fairness
- Strict, central enforcement of fairness policy, vs. Reliance on emergent behaviour with post-facto checks.
I refer the reader to the Taxonomy section of the paper for a more verbose discussion on design choices. The categories are summarised in the following diagram.
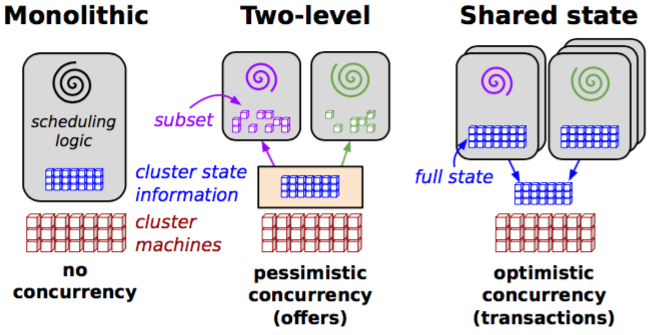
Mesos belongs to the category of two-level scheduling. The documentation for Mesos alludes to this fact by calling Mesos a level of indirection for scheduler frameworks. 4
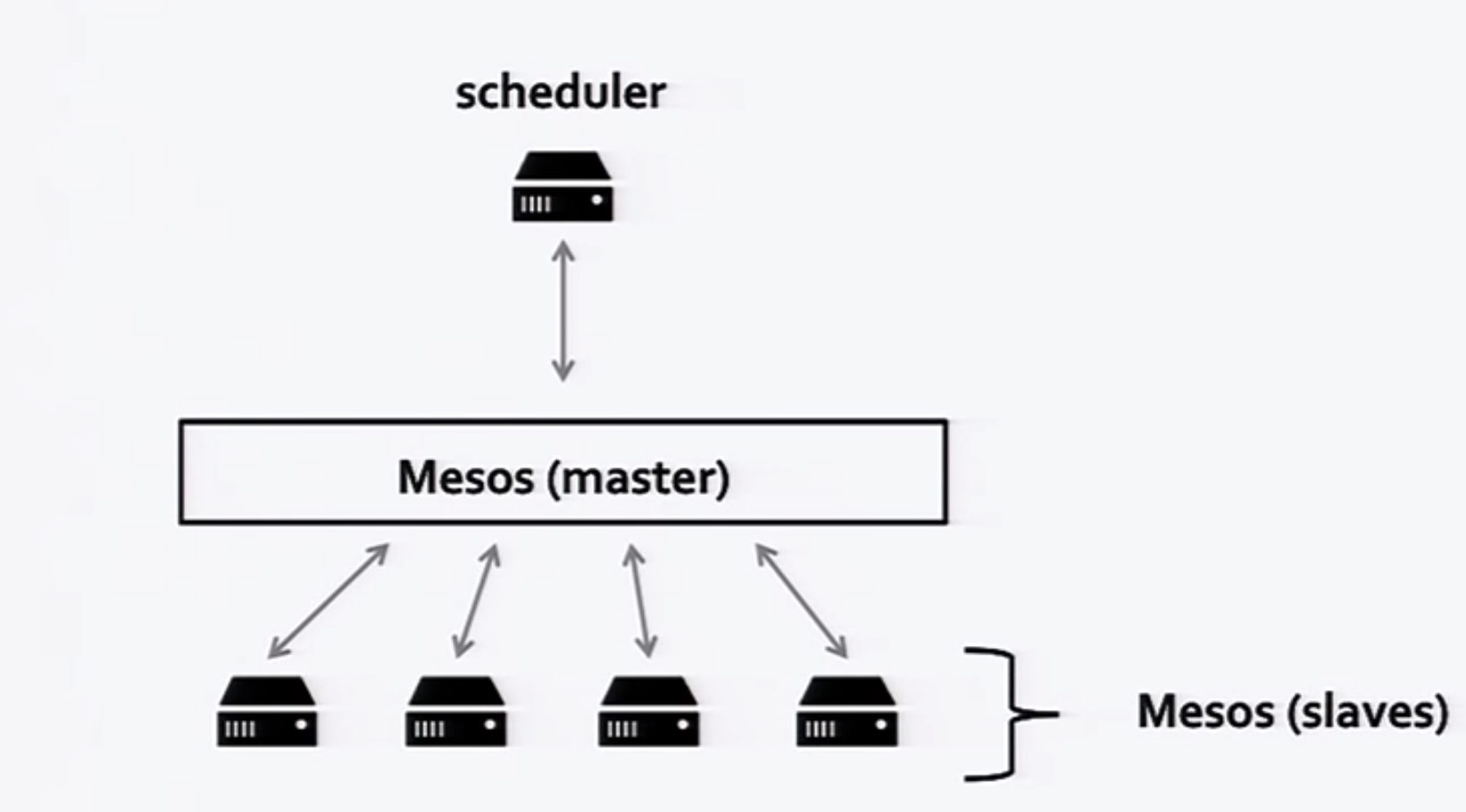
Two-Level Scheduling?
The two-level scheduling provided by Mesos can be described thus: A scheduler exists at the framework-level & another exists as part of Mesos (as a component of the Mesos master ). In a cluster with heterogenous workloads, multiple frameworks function together with a single Mesos scheduler.
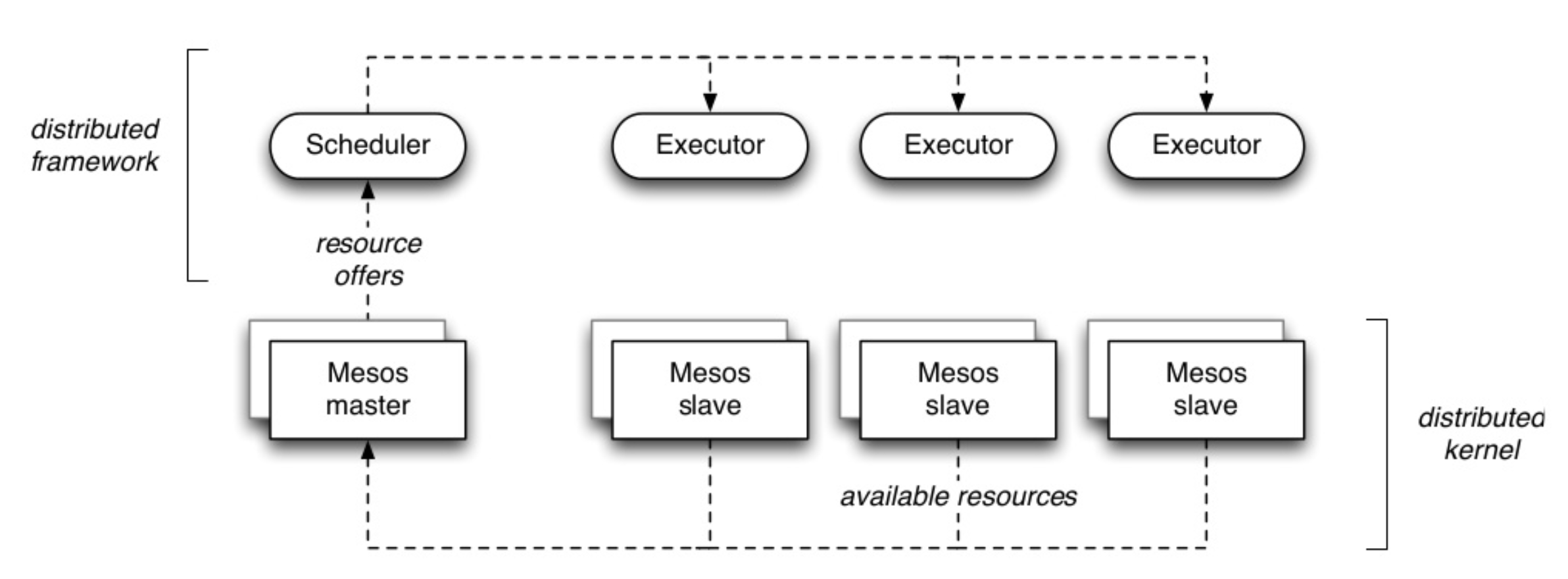
The Mesos master dynamically partitions a cluster, allocating resources to the different framework schedulers. Resources are distributed to the frameworks in the form of offers, which contain only “available” resources – ones that are currently unused. 5 An example of a resource offer is shown below.
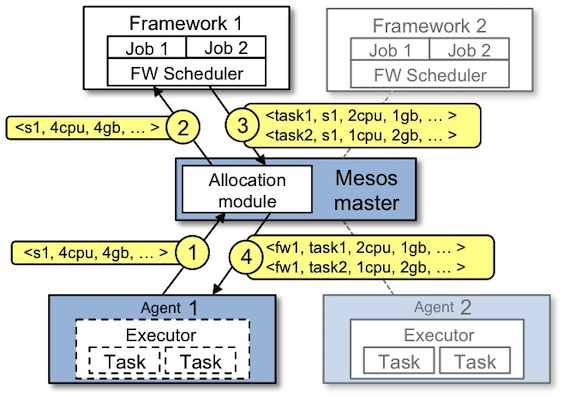
The events in the diagram are described as follows: 6
- Agent 1 reports to the master that it has 4 CPUs and 4 GB of memory free. The master then invokes the allocation policy module, which tells it that framework 1 should be offered all available resources.
- The master sends a resource offer describing what is available on agent 1 to framework 1.
- The framework’s scheduler replies to the master with information about two tasks to run on the agent, using <2 CPUs, 1 GB RAM> for the first task, and <1 CPUs, 2 GB RAM> for the second task.
- Finally, the master sends the tasks to the agent, which allocates appropriate resources to the framework’s executor, which in turn launches the two tasks (depicted with dotted-line borders in the figure). Because 1 CPU and 1 GB of RAM are still unallocated, the allocation module may now offer them to framework 2.
During offers, the master avoids conflicts by only offering a given resource to one framework at a time, and attempts to achieve dominant resource fairness (DRF) 7 by choosing the order and the sizes of its offers. Because only one framework is examining a resource at a time, it effectively holds a lock on that resource for the duration of a scheduling decision. In other words, concurrency control is pessimistic.8
A note on YARN
To contrast the above discussion with YARN, resource requests from per-job application masters are sent to a single global scheduler in the resource master, which allocates resources on various machines, subject to application-specified constraints. The application masters provide job-management services, and no scheduling. So YARN is effectively a monolithic scheduler architecture.
Closing Comments
A concise overview of the functionalities of Mesos in comparison with other resource management systems is shown in the following diagram. 9
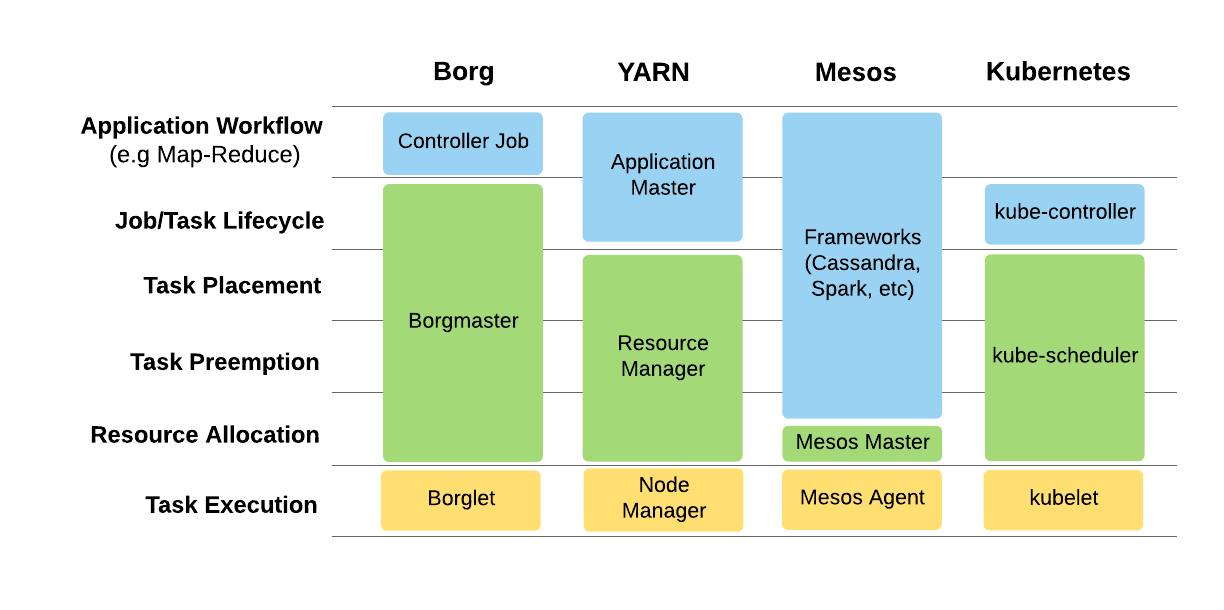
This diagram makes clear why the makers of Mesos call it the distributed systems kernel. Mesos does not try to provide every functionality a distributed system needs to function; it provides the minimum over which frameworks are expected to build on. This explains the need for schedulers & orchestration services such as Marathon, Aurora and Peloton to run your applications on Mesos. We will delve into them in a future post. Until next time!
P.S. The title illustration is from Apache Mesos as an SDK for Building Distributed Frameworks by Paco Nathan.
Notes
-
In resource management systems literature, the term co-ordinator is used interchangeably with scheduler. ↩
-
Tasks here refers to sub-units of the program which are independently schedulable. ↩
-
Herbst, Nikolas; Samuel Kounev; Ralf Reussner (2013). “Elasticity in Cloud Computing: What It Is, and What It Is Not” (PDF). Proceedings of the 10th International Conference on Autonomic Computing (ICAC 2013), San Jose, CA, June 24–28. ↩
-
A scheduler framework is the distributed system running on top of Mesos, eg. Spark, Storm, Hadoop. In other words, framework ≈ distributed system. ↩
-
This is referred to as resource choice in the Omega paper. ↩
-
From the official Mesos documentation. ↩
-
Dominant Resource Fairness is an allocation algorithm for clusters with mixed workloads, which has its origins in the same UC Berkeley research group as Mesos. ↩
-
This is termed as pessimistic interference in the Omega paper. ↩
-
This comparison is from the article on Peloton, Uber’s open source resource scheduler. ↩