Providing Streaming Joins as a Service at Facebook
01 May 2020 •PAPER-SUMMARY DATA-SYSTEMS STREAMING JOINS Providing Streaming Joins as a Service at Facebook. Jacques-Silva, G., Lei, R., Cheng, L., et al. (2018). Proceedings of the VLDB Endowment, 11(12), 1809-1821.
Stream-stream joins are a hard problem to solve at scale. “Providing Streaming Joins as a Service at Facebook” provides us the overview of systems within Facebook to support stream-stream joins.
The key contributions of the paper are:
-
a stream synchronization scheme based on event-time to pace the parsing of new data and reduce memory consumption,
-
a query planner which produces streaming join plans that support application updates, and
-
a stream time estimation scheme that handles the variations on the distribution of event-times observed in real-world streams and achieves high join accuracy.
Trade-offs in Stream-Stream Joins
Stream-stream joins have a 3-way trade-off of output latency, join accuracy, and memory footprint. One extreme of this trade-off is to provide best-effort (in terms of join accuracy) processing-time joins. Another extreme is to persist metadata associated with every joinable event on a replicated distributed store to ensure that all joinable events get matched. This approach provides excellent guarantees on output latency & join accuracy, with memory footprint sky-rocketing for large, time-skewed streams.
The approach of the paper is in the middle: it is best-effort with a facility to improve join accuracy by pacing the consumption of the input streams based on dynamically estimated watermarks on event-time.
Systems Overview
The streaming-join service is built on top of three in-house systems within Facebook: Scribe, Puma, & Stylus. A larger overview of these systems, along with other streaming systems in use within Facebook, is provided in Realtime Data Processing at Facebook.
-
Scribe is a persistent distributed messaging system that organises data in categories (like Kafka topics). Categories can be partitioned into multiple buckets, and a bucket is the unit of workload assignment.
-
Puma allows developers to write analytic jobs in a SQL-like DSL with Java UDFs called Puma Query Language (PQL).
-
Stylus is a C++ framework for building stateless, stateful and monoid stream processing operators. Stylus also provides operators the ability to replay a Scribe stream for an earlier point in time and persist in-memory state to local or remote storage.
The use of Scribe as the data transfer mechanism between operators in Stylus means that these operators can be easily plugged into a Puma query-execution DAG (in which operators are linked via Scribe as well).
Join Semantics
The system supports only inner-join and left-outer join. The join output can be all matching events within a window (1-to-n) or a single event within a window (1-to-1).
To maintain backward compatible, the system limits the changes a user can make to existing streaming joins. If the updated streaming join is significantly different, users have the option of creating a view with a new name and deleting the old one. Two examples of rules an update must follow are:
-
preservation of the join equality expression, as its modification can cause resharding of the Scribe categories
-
projection of new attributes must be specified at the end of the select list, as adding an attribute in the middle of the select list would cause the join operator to consume old attribute values as the value of a different attribute.
Query Language
For streaming-joins, the user express their joins via PQL in Puma, while the join is implemented under the hoods in Stylus. A user-defined join is defined as an application:
00: CREATE APPLICATION sample_app;
01:
02: CREATE INPUT TABLE left (
03: eventtime, key, dim_one, metric
04: ) FROM SCRIBE("left");
05:
06: CREATE INPUT TABLE right (
07: eventtime, key, dim_two, dim_three
08: ) FROM SCRIBE("right");
09:
10: CREATE VIEW joined_streams AS
11: SELECT
12: l.eventtime AS eventtime, l.key AS key,
13: l.dim_one AS dim_one, r.dim_two AS dim_two,
14: COALESCE(r.dim_three, "example") AS dim_three,
15: ABS(l.metric) AS metric
16: FROM left AS l
17: LEFT OUTER JOIN right AS r
18: ON (l.key = r.key) AND
19: (r.eventtime BETWEEN
20: l.eventtime - INTERVAL `3 minutes' AND
21: l.eventtime + INTERVAL `3 minutes');
22:
23: CREATE TABLE result AS
24: SELECT
25: eventtime, key, dim_one, dim_two,
26: dim_three, metric
27: FROM joined_streams
28: STORAGE SCRIBE (category = "result");
The join view specification above has an equality expression (line 18), and a window expressed with the BETWEEN function and using intervals on the timestamp attributes (lines 19-21).
Given a PQL query as above, it is compiled into an execution plan comprised of operators. For joins, the operators involved are :
-
Slicer : a Puma operator, similar to a mapper in MapReduce, which can ingest data from Scribe, evaluate expressions, do tuple -filtering, project columns, shard streams, and write data to Scribe, Hive, or other storage sinks.
-
Join : a Stylus operator which can ingest data from two Scribe streams, maintain the join windows, execute the join logic, and output the result into another Scribe stream.
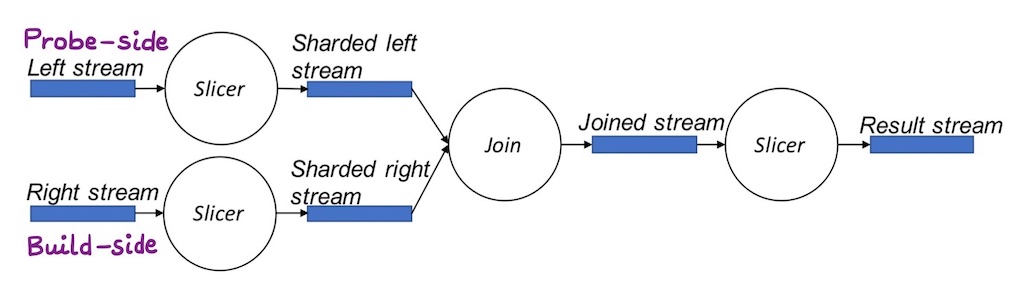
As part of the pre-join transformations on both the left (probe-side) & right side (build-side), projections are resolved, join equality & timestamp expressions are computed, and the streams are sharded as per the join-equality attribute & written into intermediary Scribe categories.
Since only inner joins or left-outer joins are supported by the system, the expressions of the left-side are evaluated before join while for the right-side, this is done after the join.
The Join Operator
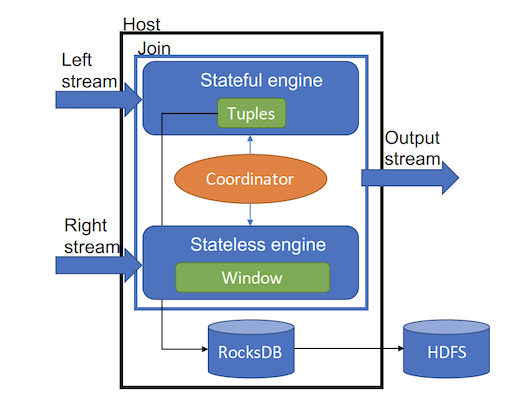
As shown in Figure 2, the join operator has 3 components: (i) a stateful engine, used to process the left stream, (ii) a stateless engine, processing the right stream, and (iii) a coordinator, to bridge the two engines together.
Left stateful engine : As events in the left stream are processed, the stateful engine looks-up matching events in the right join window. In case of a successful lookup, join results are generated. If there are no matches, the event is retained (till the window closes) in the buffer to retry later.1
Right stateless engine : The stateless engine ingests the right stream and maintains a window of events that matches the specified join window for the incoming left stream events. The window is trimmed at regular intervals to expel events outside the join window. This happens when the dynamically estimated processing time for the stream moves forward.2
Coordinator : The coordinator brings both engines together by providing APIs for the left engine to look up matching events in the right engine, and for both engines to query the other stream’s dynamically estimated processing time.
Dynamically Estimated Processing Time
A stream property called processing time is used in the synchronisation of the two streams. Stream synchronisation is essential to limit the memory required to buffer events needed for matching. This section is a brief overview of processing time; while the next section describes its use in stream synchronisation.
Processing Time (PT) indicates the estimated time of a stream : a time for which we estimate that there will be no new events whose event-time has a value that is smaller than the processing time.3 To compute a stream’s PT, it is divided into micro-batches with configurable size. The PT for a micro-batch is then computed. Events in future micro-batches are expected to have event-time > PT.4
The sizing of micro-batches is crucial. Larger micro-batches provide better estimates of PT 5, but increase latency in the system.
Synchronising Streams
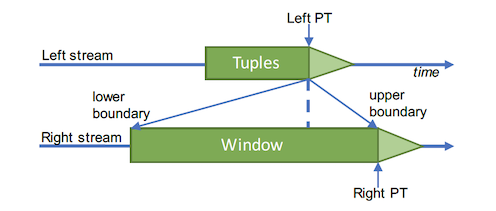
Each stream computes its PT independently. Stream synchronisation is performed by pausing the stream that has its PT too far ahead of the other. Synchronization uses the following formula:
\[\mathsf{ PT_{left} + Window_{upper} = PT_{right}}\]where \(\mathsf{ PT_{left}}\) represents the processing time estimated for the left stream, \(\mathsf{ PT_{right}}\) is the processing time for the right stream, and \(\mathsf{Window_{upper}}\) is the upper boundary of the window.
Performance Evaluation
Join Accuracy
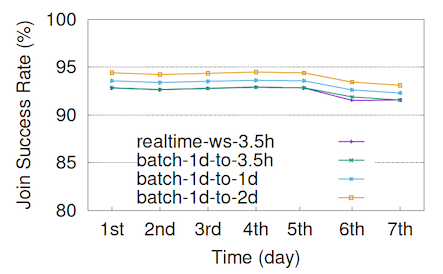
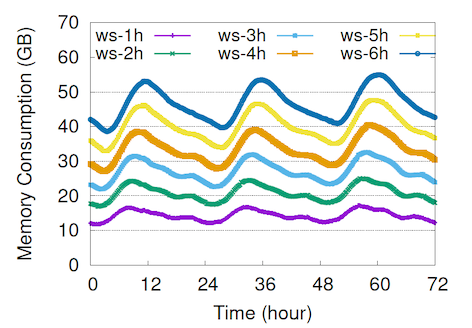
Join Window Size vs. Memory Consumption
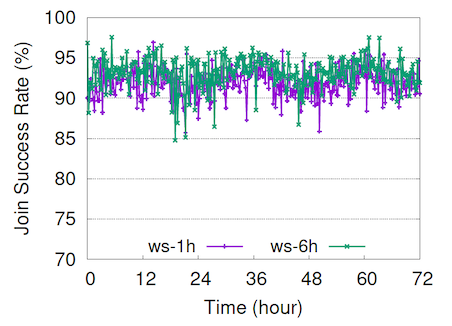
Join Window Size vs. Join Success Rate
Footnotes
-
The stateful engine persists state into a local RocksDB instance and replicates it asynchronously to remote HDFS clusters, and hence, called stateful. ↩
-
Although it maintains an in-memory state, the engine is stateless from a system perspective. It does not checkpoint to local or remote storage. It relies on replaying data from Scribe categories for fault-tolerance. ↩
-
In Stylus, the processing time is implemented as a percentile of the processed event times, similar to Millwheel. ↩
-
If the statistic for PT is an x percentile statistic, the assumption is that any future micro-batch will have at most x% of events with an event-time < PT. ↩
-
A better estimate of PT is that which fulfills the low watermark assumption that at most x% of events processed after a given PT will have an event-time smaller than it. ↩