Integration of Large-Scale Data Processing Systems and Traditional Parallel Database Technology
14 Sep 2019 •PAPER-SUMMARY DATA-SYSTEMS DATABASES Integration of Large-Scale Data Processing Systems and Traditional Parallel Database Technology Abouzied, A., Abadi, D.J, Bajda-Pawlikowski, K., Silberschatz, A. (2019, August). Proceedings of the VLDB Vol. 12 (12).
HadoopDB was a prototype built in 2009 as a hybrid SQL system with the features from Hadoop MapReduce framework and parallel database management systems (Greenplum, Vertica, etc). This paper revisits the design choices for HadoopDB, and investigates its legacy in existing data systems. I felt it is a great review paper for the state of modern data analysis systems.
MapReduce is the most famous example in a class of systems which partition large amounts of data over multitude of machines, and provide a straightforward language in which to express complex transformations and analyses. The key feature of these systems is how they abstract out fault-tolerance and partitioning from the user.
MapReduce, along with other large-scale data processing systems such as Microsoft’s Dryad/LINQ project, were originally designed for processing unstructured data.
The success of these systems in processing unstructured data led to a natural desire to also use them for processing structured data. However, the final result was a major step backward relative to the decades of research in parallel database systems that provide similar capabilities of parallel query processing over structured data. 1
The MapReduce model of Map -> Shuffle -> Reduce/Aggregate -> Materialize is inefficient for parallel structured query processing.
1) .. database systems are most efficient when they can pipeline data between operators. The forced materialization of intermediate data by MapReduce - especially when data is replicated to a distributed file system after each Reduce function - is extremely inefficient and slows down query processing.
2) MapReduce naturally provides support for one type of distributed join operation: the partitioned hash join. In parallel database systems, broadcast joins and co-partitioned joins when eligible to be used are frequently chosen by the query optimizer, since they can improve performance significantly. Unfortunately, no implementation of broadcast and co-partitioned joins fit naturally into the MapReduce programming model.
3) Optimizations for structured data at the storage level such as column-orientation, compression in formats that can be operated on directly (without decompression), and indexing were hard to leverage via the execution framework of the MapReduce model.
In spite of these shortcomings, there are valid technical (and non-technical) reasons for the wide adoption of Hadoop for structured data processing.
- Fault-tolerance in Hadoop during run-time query processing.
- Ability to handle heterogenous clusters
- Ability to parallelize user defined functions.
HadoopDB was designed to take advantage of these technical prowesses of Hadoop, while addressing its shortcomings.
HadoopDB placed a local DBMS (PostgreSQL/VectorWise) on every node in the data processing clusters. This enabled significant speedup in the Map tasks, as filtering, projection, transformation, certain joins and, partial aggregations were pushed into the local DBMS.
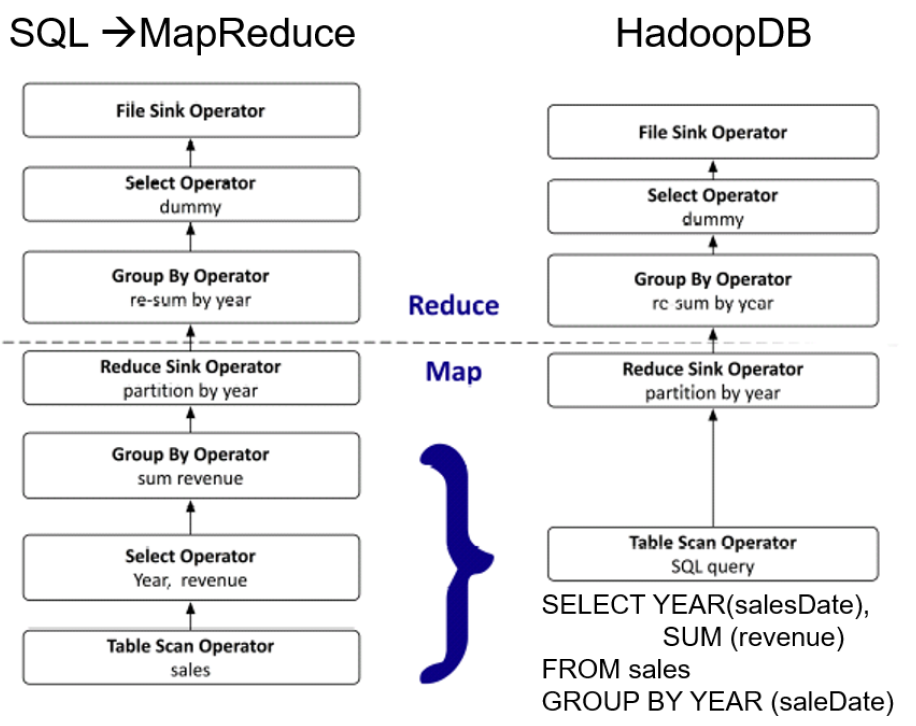
The desirable properties of HadoopDB as a data processing framework were:
- Querying could be done in SQL, MapReduce or a combination thereof.
- Ability to handle heterogenous clusters; a trait derived from Hadoop.
- Fault-tolerance; another trait derived from Hadoop.
HadoopDB leveraged Hadoop’s checkpointing of intermediate data to disk after Map tasks, along with the determinism of Map and Reduce tasks in the MapReduce model to implement mid-query fault tolerance and thereby scale to very large deployments.
- HadoopDB with VectorWise was able to consistently outperform Hive and a commercial DBMS.
Research Contributions
Split Execution
- Split MapReduce/Database Joins : In case of broadcast joins, HadoopDB chooses either of two strategies: i) A Map-side broadcast hash join, or ii) Insert the smaller table into the DBMS as a temporary table, and perform the join within the DBMS at each node.
- Partial Aggregations : Based on heuristics, partial aggregations were used in
join + aggregationstype of queries to either prevent unnecessary writes to HDFS, or to improve query performance.
Other contributions listed include Invisible Loading, Sinew, and Automatic Schema Generation.
Review of SQL-on-Hadoop
HadoopDb demonstrated the performance benefits of columnar data storage in the Hadoop ecosystem. The Hadoop community followed it with the introduction of columnar storage capability into HDFS file formats, namely Parquet and ORC.
Parquet and ORCFile use PAX blocks for columnar storage. In PAX, data is kept in columns within blocks, but a given block may consist of multiple columns from the same table. This makes tuple reconstruction faster since all data needed to perform this operation can be found in the same block. On the other hand, PAX reduces scan performance compared to pure column stores since not all data for a given column is placed contiguously on disk. 2
The next-wave of SQL-on-Hadoop systems utilised the performance of columnar storage, and were architected as system-level integrations of parallel databases and large-scale data processing systems.
Hive evolved from a language-level hybrid to a system-level hybrid, incorporating pluggable execution engines. Tez, similar to Dryad, was one of the execution engines borne out of this effort. An additional layer of processing called LLAP was introduced.
LLAP (Live Long and Process) … introduced per-node daemons responsible for local query execution and caching hot data. In essence, LLAP instances served a similar purpose in Hive as local DBMS servers in HadoopDB.
Apache Calcite was incorporated into Hive to provide cost-based optimizations. ORC ACID provided transactional table support.
Spark, which has similarities to Dryad and Tez, had significant performance gains over MapReduce in iterative data processing. SparkSQL brought in SQL capabilities to Spark. Delta is a transactional table storage for Spark built on Parquet.
Impala and HAWQ, like HadoopDB, include a specialized single-node query execution engine in a Hadoop cluster. They differ in the fact that intra-node communication is not managed by MapReduce. They have a complete parallel database system to manage intra-node communication, and thus entire query plans can circumvent MapReduce. This results in a loss of mid-query fault-tolerance.
Presto is also a complete parallel database system. Like Impala, Presto fully pipelines relational operators. This means faster query execution and no support for mid-query fault-tolerance.
By being complete implementations of parallel execution engines, Impala, HAWQ, and Presto are somewhat independent systems that integrate with Hadoop mostly at the storage level (although Impala and HAWQ both also integrate with Hadoop’s resource management tools). To that end, they provide similar (albeit more native) functionality to a large number of commercial parallel database systems that have “connectors” to Hadoop that enable them to read data from HDFS.
Footnotes
-
DeWitt, David, and Michael Stonebraker. “MapReduce: A major step backwards.” The Database Column. ↩
-
As noted by Dmitriy Ryaboy here, the combined effect of large block sizes (~256 MB in case of ORC and 512-1024MB for Parquet in standard deployments) and parallel reader processes diminishes the significance of the PAX “weaving pattern”. ↩