Dynamo vs Cassandra : Systems Design of NoSQL Databases
02 Oct 2018 •DATA-SYSTEMS NOSQL DATABASES State-of-the-art distributed databases represent a distillation of years of research in distributed systems. The concepts underlying any distributed system can thus be overwhelming to comprehend. This is truer when you are dealing with databases without the strong consistency guarantee. Databases without strong consistency guarantees come in a range of flavours; but they are bunched under a category called NoSQL databases.
NoSQL databases do not represent a single kind of data model, nor do they offer uniform guarantees regarding consistency and availability. However, they are built on very similar principles and ideas.
From a historical perspective, the advent of NoSQL databases was precipitated by the publication of Dynamo by Amazon1 & BigTable by Google, and the emergence of a number of open-source distributed data stores, which were (improved?) clones of either (or both) of these systems. Bigtable-inspired NoSQL stores are referred to as column-stores (e.g. HyperTable, HBase), whereas Dynamo influenced most of the key/value-stores. We will term these systems loosely as Dynamo-family databases, which include Riak, Aerospike, Project Voldemort, and Cassandra.
I would like to focus on systems design ideas in Dynamo-family NoSQL databases in this article, with a particular focus on Cassandra. The approach of this article is to compare and contrast Cassandra with Dynamo; and in this process, touch upon the underlying ideas. Expect a lot of homework & further readings; I will have copious amounts of references throughout the article.
Caveats
Cassandra, although heavily influenced by Dynamo, also borrows from BigTable.
A chunk of the differences between Cassandra & Dynamo stem from the fact that the data-model of Dynamo is a key-value store, while Cassandra is designed as a column-family data store (which is a concept from BigTable in which the primary abstraction is a sparsely populated wide table).
For what it’s worth, Cassandra is full-fledged database implementation while Dynamo is a set of ideas which when taken together can form a highly available distributed data-store (courtesy of it being a walled system with its implementation never released to public domain).
We will focus on a comparison of the implementation choices in Cassandra & Dynamo which address the challenges of a distributed system; and will try to steer clear of contrasts arising from differences in the data models.
Meat of the Matter
The essence of this article can be summarized as below:
| Problem | Dynamo | Cassandra |
|---|---|---|
| High Availability for Writes | Vector Clocks | Last Write Wins |
| Temporary Failures | Sloppy Quorum & Hinted Hand-offs | Strict Quorum & Hinted Hand-offs |
| Partitioning | Consistent Hashing | Consistent Hashing |
| Permanent Failures | Anti-entropy using Merkle trees | Anti-entropy using Merkle trees |
| Failure Detection | Gossip Protocols | Gossip Protocols |
The remainder of this article is little more than a collection of introductions to the above concepts.
High Availability for Writes
High-availability writes in a distributed database with leaderless replication (both Dynamo and Cassandra employ leaderless replication) requires a heuristic for conflict resolution between concurrent writes. This is essential because every replica of data is considered equal and concurrent writes on the same record at two different replicas are considered perfectly valid.
The common heuristics for conflict resolution are vector clocks or last-write-wins.
Vector Clocks
Vector Clocks are a mechanism to notify the actors about the occurrence of conflicts.
To illustrate the process, assume three actors with actor IDs Anu, Baba and Chandra respectively. Let an existing data-point in the data-store be {"street" : "Lavelle", "city" : "Bangalore"} with key ‘address’. We will call this version of ‘address’ V0. Anu updates the street such that the data now reads {"street" : "Cubbon", "city" : "Bangalore"}, which we will call V1. This is updated to a single replica. A concurrent update is performed by Baba, who changes the city such that the data now reads {"street" : "Lavelle", "city" : "Bombay"} (V2 ). This is updated to another replica.
In a data-store using vector clocks, the data-store holds onto both V1 and V2 because they do not descend from each other. When an actor reads the data at a future point of time (for example, Chandra is reading the ‘address’ data), the data-store will hand back both values. The client decides on the merge strategy of the sibling data returned to it. Once descendancy can be calculated, values stored with vector clocks that have been succeeded will be removed.
Vector Clocks were proposed as a conflict resolution mechanism in the original Dynamo paper; however, most Dynamo-family databases have last-write-wins as their conflict resolution mechanism.2
The maintainers of Riak have lucid explanations of how vector clocks work and the associated challenges in Why Vector Clocks Are Easy and Why Vector Clocks Are Hard.
Last Write Wins
In last-write-wins, the latest change to a data-point alone is retained. Thus, in the above example, V2 will be the final version of the data in a last-write-wins data-store. Thus, last-write-wins is a simplification over the vector clock approach. It could lead to potential data loss (such as the update to ‘street’ introduced in V1 is lost).
The maintainers of Cassandra believe this simplification is justified because of the data model is different from a key-value database. Each row is broken up into columns which are updated independently. This fine-grained implementation of last-write-wins is argued to work well for Cassandra. In case of time-ties for the same column, Cassandra has a rule-based, deterministic method to get a commutative result. You can read more on why Cassandra doesn’t need vector clocks here.
Temporary Failures
Temporary failures occur when a replica is unavailable for read and/or write operations for a small duration of time. This could arise because of GC stalls, network and hardware outages, or maintenance shutdowns.
Hinted Handoff is a common strategy in write paths to handle and repair temporary failures in systems with leaderless replication. In read paths, the approach for handling temporary failures could be either strict or sloppy quorum.
Hinted Handoff
In Hinted Handoff, when a write is performed and a replica node for the row is either known to be down ahead of time, or does not respond to the write request, the coordinator will store a hint locally. This hint is basically a wrapper around the mutation indicating that it needs to be replayed to the unavailable node(s).
Once a node discovers via gossip that a node for which it holds hints has recovered, it will send the data row corresponding to each hint to the target.
Hinted Handoff has two purposes:
- It allows the database to offer full write availability when consistency is not required.3
- It improves response consistency after temporary outages.4
The implications of hinted writes on read & write consistencies are covered in the next section on strict & sloppy quorum. Notes on Cassandra’s implementation of hinted handoff can be found here.
Strict & Sloppy Quorum
Quorum is the number of replicas which should acknowledge a particular read or write operation; it is closely associated with the replication factor. The use of hinted writes to meet consistency requirements in read paths decides whether a quorum is strict or sloppy.
In Dynamo, in scenarios where the available replicas is less than the total replicas, sloppy quorum is used to ensure read availability. The hinted writes stored in a node other than the replicas count towards read consistency requirements, and thus reads can be served even in cases where available replicas is less than the consistency requirements.
In Cassandra, strict quorum is used. This means that hinted writes do not count towards read or write consistency requirements (with the exception of ANY write consistency).
Consistent Hashing
This article started with saying that distributed databases represent a distillation of years of research in distributed systems. No other concept illustrates this better than consistent hashing (or ring hashing). Consistent hashing has been around since 1997 5, and formed the basis of the formation of Akamai Technologies, and the subsequent birth of the Content Distribution Network industry.
In consistent hashing, the output range of a hash function is treated as a fixed circular space or “ring” (i.e. the largest hash value wraps around to the smallest hash value). Each node in the system is assigned multiple random value within this space. Each random value is called a vnode position; a single node is associated to multiple vnodes & consequently multiple positions on the ring.
Each data item identified by a key is assigned to a node by hashing the data item’s key to yield its position on the ring, and then walking the ring clockwise to find the first vnode with a position larger than the item’s position. The node associated with the vnode is the location of the data item.
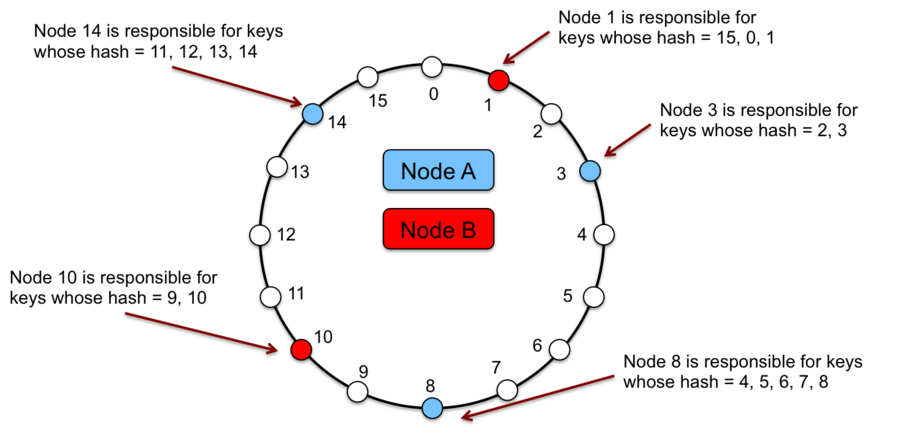
The principle advantage of consistent hashing is incremental stability; the departure or arrival of a node into the cluster only affects its immediate neighbours and other nodes remain unaffected.
However, ring hashing is prone to uneven load distribution. The table below, taken from the paper on Jump Hash (an alternative algorithm to ring hash), shows the standard error in loads & the 99% confidence interval of bucket sizes as multiples of average loads.
| Points per Bucket | Standard Error | Bucket Size 99% Confidence Interval |
|---|---|---|
| 1 | 0.9979060 | (0.005, 5.25) |
| 10 | 0.3151810 | (0.37, 1.98) |
| 100 | 0.0996996 | (0.76, 1.28) |
| 1000 | 0.0315723 | (0.92, 1.09) |
This table can be read in the following way: in an implementation with 10 vnodes per node, the standard deviation of load is within (1 - 0.3151810) ≈ 0.69. The 99% confidence interval for the bucket sizes lies between 0.37 to 1.98 times the average load. Such a high variance could make capacity planning tricky (although I am yet to see this in practice with Cassandra). In Cassandra, the number of vnodes is controlled by the parameter num_tokens.
Consistent hashing is also a part of the replication strategy in Dynamo-family databases. In Cassandra, two strategies exist. In SimpleStrategy, a node is anointed as the location of the first replica by using the ring hashing partitioner. Subsequent replicas are placed on the next nodes clockwise on the ring. In NetworkTopologyStrategy, for each datacenter, the same steps are performed with a difference when choosing subsequent replicas: subsequent replicas are placed on the next node clockwise on the ring which belongs to a different rack than the location of the previous replica.
The use of consistent hashing in Voldemort and Riak follow the same above-illustrated pattern. An excellent primer on alternatives to ring hashing & their respective trade-offs can be found here.
Anti-Entropy using Merkle trees
The distributed nature of data means data in a replica can become inconsistent with other replicas over time. Dynamo-family databases have a multi-pronged approach to deal with it. Hinted Hand-offs is a strategy in write-paths to handle and repair temporary failures. Read repair is a strategy to repair inconsistencies observed in the read-path.
The above two strategies work behind the scene to repair data; but due to their very nature of repairing data accessed during reads or writes alone, they cannot repair every data item in the replicas. They work best if the system membership churn is low and node failures are transient. Hence, these databases provide a manual way to trigger repairs of data. This is called an anti-entropy repair. 6
Anti-entropy is a process of comparing the data of all replicas and updating each replica to the newest version. It relies on Merkle tree hash exchanges between nodes. The following extract, from Cassandra documentation, is a good overview of the use of Merkle trees in the anti-entropy process.
Merkle trees are binary hash trees whose leaves are hashes of the individual key values. The leaf of a Cassandra Merkle tree is the hash of a row value. Each Parent node higher in the tree is a hash of its respective children. Because higher nodes in the Merkle tree represent data further down the tree, Casandra can check each branch independently without requiring the coordinator node to download the entire data set.
After the initiating node receives the Merkle trees from the participating peer nodes, the initiating node compares every tree to every other tree. If a difference is detected, the differing nodes exchange data for the conflicting range(s), and the new data is written to SSTables. The comparison begins with the top node of the Merkle tree. If no difference is detected, then the data requires no repair. If any difference is detected, the process proceeds to the left child node and compares and then the right child node. When a node is found to differ, inconsistent data exists for the range that pertains to that node. All data that corresponds to the leaves below that Merkle tree node will be replaced with new data.
The key difference in Cassandra’s implementation of anti-entropy from Dynamo is that the Merkle trees are built per column family, and they are not maintained for longer than it takes to send them to neighboring nodes.7 Instead, the trees are generated as snapshots of the dataset during major compactions: this means that excess data might be sent across the network, but it saves local disk IO, and is preferable for very large datasets.
Notes on Cassandra’s implementation of anti-entropy can be found here. A more-detailed blog-entry on anti-entropy, with a similar take on comparing Riak, Cassandra & Dynamo as this article, can be found here.
Gossip Protocols
Gossip protocols are a class of peer-to-peer communication protocols inspired by information dissemination in real-life social networks. In Dynamo, decentralized failure detection protocols use a simple gossip-style protocol that enable each node in the system to learn about the arrival (or departure) of other nodes. Failure detection helps nodes in avoiding communication with unresponsive peers during read and write operations. Dynamo’s failure detection protocol is based on Gupta et al. (2001), although the exact implementation details are obscure.
The Cassandra implementation of gossip is very similar to Dynamo, and we have a lot more information on it via its documentation. The gossip process runs every second and exchanges state messages with up to three other nodes in the cluster. The nodes exchange information about themselves and about the other nodes that they have gossiped about, so all nodes quickly learn about all other nodes in the cluster. A gossip message has a version associated with it, so that during a gossip exchange, older information is overwritten with the most current state for a particular node.
The gossip process tracks state from other nodes both directly (nodes gossiping directly to it) and indirectly (nodes communicated about secondhand, third-hand, and so on). Rather than have a fixed threshold for marking failing nodes, Cassandra uses an accrual detection mechanism to calculate a per-node threshold that takes into account network performance, workload, and historical conditions. During gossip exchanges, every node maintains a sliding window of inter-arrival times of gossip messages from other nodes in the cluster. Configuring the phi_convict_threshold property adjusts the sensitivity of the failure detector.
That’s All, Folks!
The scope of topics covered in this article are vast; and I do not believe a single article does justice to them. However, the attempt here was to compile a compendium on the ideas behind NoSQL distributed systems. A future article will attempt a similar take on NewSQL databases, but that’s for another day. Hope you find this useful. Until next time!
Notes
-
A fair amount of review-articles exists for the Dynamo paper: a few interesting takes can be found here & here. ↩
-
Riak has last-write-wins as its default mechanism for conflict resolution, inspite of a high chance of data-loss. As its maintainers put it,
-
The catch here is ‘when consistency is not required’. In Dynamo which uses sloppy quorum, hinted writes count towards write consistency requirements, and hence hinted handoff helps offer full write availability.
In Cassandra, for every write consistency other than ANY, hinted writes do not count towards write consistency requirements. Hence, full write availability may not be available. ↩
-
In a similar vein to the note above, sloppy quorum in Dynamo means that hints stored in nodes other than the replicas count towards read consistency requirements; thus, improving read availability.
Cassandra does not use hinted writes in computing read consistency requirements; thus hinted handoffs do not improve read availability. ↩
-
This may not be entirely true. A form of consistent hashing is claimed to have existed in Teradata since 1986. I could not find any source to back this claim. However, it is clear the Akamai paper was the first to name this technique as consistent hashing. ↩
-
Anti-entropy processes need not always be manual. Riak periodically clears & regenerates the Merkle hash trees used in the anti-entropy process. They term it active anti-entropy. ↩
-
Cassandra does not persist the hash trees generated during anti-entropy.
On the other hand, Riak (which seems to have followed the original Dynamo approach on this) uses persistent, on-disk hash trees instead of in-memory hash trees. The advantages of this approach, as stated by its maintainers, are twofold:
a) Riak can run anti-entropy operations with a minimal impact on memory usage.
b) Riak nodes can be restarted without needing to rebuild hash trees. ↩