Product Articles
-
The best-case scenario would be if we are able to leverage the definition to identify opportunities to build internal platforms (“Does Y require a platform?” ). ↩
-
Although I mention the example of a back-office of accountants here (for effect), eliminating it from any definition of a platform is easy. We can differentiate the same way we differentiate any automation from a manual performance of the same task: by introducing the constraint of consistent repeatability. Humans are error-prone in performing repetitive tasks, machines are less so. ↩
-
I use number of users here as a proxy for usage. Depending on the exact service provided by the platform, usage might not be a function of number of users alone (for example, number of API calls). ↩
-
AWS S3 was famously never designed for Data Lakes, but that is one of the major use-cases for S3 nowadays. ↩
-
To define a platform for the purposes of this post, I use Camille Fournier’s words: A platform is the software side of infrastructure. ↩
-
I use AWS throughout this article as a stand-in for a generic cloud provider. ↩
-
Although I do not mention data abstractions provided by data platform teams specifically here, the arguments in this article hold just as true. ↩
-
The other function, in many cases, turns out to be another engineering team. eg. a team of backend engineers reliant on the tooling provided by the infrastructure team for the provisioning of servers. ↩
-
As anyone aware of product management for consumer products, this is gross reductionism; but let us take it at face value for the sake of the narrative I want to focus on. ↩
-
Metrics have an overloaded meaning here. To clarify, your team might have good observability metrics to understand the need to design better solutions to scale existing features, but no metrics to make the case for new features. ↩
- training members: investing in people,
- improving process: investing in shaping behaviour and communication,
- staking technical leverage: investing in technology.
Defining a Platform is Hard
07 Jun 2021 •PLATFORMS PRODUCT MANAGEMENT Engineering platforms are a vague concept. Software organisations across the board agree on the need to ‘platformise’ layers of their stack, but struggle to define the term. The question ‘what is a platform’ is met with a response ‘something similar to AWS, but at a higher layer of the company software stack’. I have previously argued why this is a false analogy.
I think we can agree that there is a dichotomy in engineering platforms: public platforms and internal (or private) platforms. AWS S3, Snowflake, and others are examples of public platforms, while internal platforms are engineering platforms built within a software organisation to serve internal users.
My approach here is to start with a reasonable definition of platforms in general and arrive at a reasonable definition for internal platforms. This was not as straightforward as it sounds. The minimum we can gain from such an exercise is the ability to identify internal platforms in the wild (“Is X an internal platform?” ). 1
So, what is a platform?
The Bill Gates’ definition of a platform goes like this:
A platform is when the economic value to everybody that uses it, exceeds the value of the company that creates the platform.
This is a succinct description but the trouble with it is that it is a post-hoc definition: it can only identify a platform after it has started accruing value for the creators and users. Like a lagging indicator, this is useful in a limited sense. But as you might have noticed, the question we look to answer is also post-hoc (“Is X an internal platform?” ). Thus the Gates’ definition can be our initial template for a definition of internal platforms.
How can the above be paraphrased for internal platforms? Assuming that a company can be seen as a set of coordinating units or teams, we might say, ‘an internal platform is when the economic value to every team that uses it, exceeds the cost of the platform’.
So, by this definition, in a simple case where there is a single ‘software platform’ used by \(m\) product teams, each of which has \(n\) customers with a uniform revenue of \($R\) per customer, the cumulative value \(n * m * R\) should (greatly) exceed \(C\), the cost-to-company of the platform.
This definition is almost useless. Unlike the original Gates’ quote, it does not help us identify platforms from non-platforms. Everything within a company, from a set of APIs to a team of accountants in the back-office 2, could pass off as a platform under this definition. Let us refine this further using what we know about internal platforms, and their distinct attributes.
Cost
Before we turn to the attributes of an internal platform, a brief note on cost. As we have already seen in the above attempted definitions, the terms ‘cost’ and ‘value’ are central to the formulations. I would like to expand a bit on the term ‘cost’ in the context of internal platforms.
The term ‘cost’ includes the dollar cost of operating the platform as well as a measure of the effort required by users to use the internal platform. How do we measure the effort required by users to use the internal platform? I have previously talked about how abstractions provided by internal platforms have to cater to an entire spectrum of users within the company, and not the median users of the system. A measurement of the effort required by users to use the internal platform is essentially a weighted average of the usability index of the platform for every user persona the platform caters to.
Attributes of an Internal Platform
So what desirable properties do internal platforms have?
Scalable
Platforms inherently have to be scalable.
A typical engineering definition of scalability would be along the dimensions of reliability and fault-tolerance; the system should be reliable and fault-tolerant as usage of the system increases. But for a platform, we need to consider cost scalability as well: the marginal cost of the platform should diminish as usage increases.
An illustration of the property of cost-scalability is as follows: Consider a platform with \(n\) users and an operating cost of \(C\). Assume that when the user-count increases to \(n+1\), the cost increases to \(C+ c_{1}\), and when the user-count increases to \(n+1\), the cost increases to \(C+ c_{1} + c_{2}\). For a cost-scalable platform, \(c_{2} \leq c_{1}\). 3
Lasting
A ‘lasting’ platform ensures that the incremental cost to the customer grows more slowly than the incremental value to the customer.
In case of public platforms, not every platform has to be lasting. Byrne Hobart calls (public) platforms which follow the incremental value dictum as second-derivative platforms (a first-derivative platform being one which follows the Bill Gates’ definition above).
Internal platforms always have to be lasting (a.k.a. second-derivative).
Serendipitous
Every platform has users who use them for use-cases they were not designed for. 4 This also implies that a platform caters to multiple sets of users (target audiences and otherwise). I call this being serendipitous.
Contrary to the other attributes, being serendipitous is an attribute of internal platforms which can be leveraged to predict where to build an internal platform. I have previously talked about how overloaded use-cases within a platform are a good guide to learn about the unmet needs of the users. This is true even in cases where a platform has not yet been built. APIs with overloaded use-cases are excellent indicators that a platform with more general abstractions should probably take its place.
There is another explanation of why no true platform 5 will only cater to a single user persona. Internal platforms are essentially monopolies within a company for a certain value-producing activity. And monopolies tend to commodify their adjacent in the value chain. If you consider the product teams or other internal users using the internal platform as the layer adjacent to the platform in the value chain of the company, it follows naturally that internal platforms should cater to a wide spectrum of users (or use-cases) which it commodifies.
Final Take?
A definition for internal platforms in the light of these attributes could be stated as:
An internal platform is when a scalable, commodifying, coherent set of APIs ensures that the incremental cost to the customer grows more slowly than the incremental value to the customer.
Footnotes
AWS Is NOT Your Ideal
01 Oct 2020 •PLATFORMS PRODUCT MANAGEMENT Let me start with an assertion. Every platform engineering team 1 in every organisation aspires to be like AWS 2.
Every platform team wants to be like AWS, because like AWS, they provide infrastructure abstractions to users. AWS provides infrastructure via the abstractions of VMs and disks and write-capacity-units, while platform teams provide infrastructure using higher abstractions which solve service definitions, database or message queue provisioning, and service right-sizing 3.
This similarity prompts leaders of platform engineering teams to model their teams as agnostic providers of universal, non-leaky (within SLO bounds), self-served abstractions for their engineering organisation. Platform teams structured as such detached units struggle to define cohesive roadmaps which provide increasing value to business. But how does your platform differ from AWS?
Your Platform vs. The Platform
1. The Middle Ground
As an agnostic service provider, AWS can afford to cater to median use-cases. The reason platform engineering teams exist is to bridge the gap between PaaS abstractions which work for the median use-case to your business’ specific use-cases. AWS can afford to target the median (economy of scale etc.), but you cannot.
Agnostic platform engineering teams which emulate AWS try to get away from this responsibility by proposing abstractions which target the median use-case. A tell-tale sign of this is when the lack in wide usability of internal abstractions is compensated for by extensive onboarding & repeated training. This is also a side-effect of the relative valuation of engineering time vs. the time of another function 4.
2. Follow the Money
The dictum ‘follow the money’ works beautifully for customer-front products. When faced with a choice between two competing features to prioritise, a common tactical play is to make something which leads to more (immediate & long-term) revenue. The proxy for increased revenue could be increased acquisition conversion, better retention or improved user experience – metrics which ensure increased revenue for the company over time. In short, revenue growth is the north star 5.
Not so much in platform engineering. There is no revenue since your customers are internal, captive ones. Captive audiences are forced to use a solution by the force of dictum and lack of choice. The metrics used in platform products are proxies for usability and user satisfaction – but there are no foolproof ways to measure it for captive audiences. For captive audiences, solutions can not compete and better solutions cannot win. Like a command economy, platform products are designed rather than evolved. Design takes priority over market economy. So why is design bad?
Bad Design
For design to work, there has to be an objective function against which we can design. A specification is an objective function against which engineering teams design a solution. Since we do not have reliable metrics 6 to rely on for platform engineering, how do we come up with specifications? And without rigorous specifications, new features created by the platform run a high risk of not solving worthwhile problems for the users. The current accepted methodology among platform engineering leaders to solve this paucity of specifications is to rely on user-interviews. This is, as mentioned before, an unreliable source since captive users do not have the best view of the ideal state of tooling and abstractions that could be available to them.
The only way to flip this situation is to let go of command-economy-style designed abstractions, and to let your platform self-organise along the principle of markets. How does that look in practice?
1. Market, FTW
Camille Fournier mentions in Product for Internal Platforms how her team partners with customer teams to develop prototypes for specific problems. These specific solutions are later honed and iterated on to become general solutions provided by your team. I would go a step further on this route, where possible. Partner to prototype with multiple teams facing related problems to develop multiple specific solutions. These specific solutions can be seen as competing candidates to solve a general problem. Bring in user-interviews at this point to gauge pain-points, and iterate individually on these specific solutions. This switches the economy of your team to a self-organised market. Once considerable thought and iteration has gone into each solution, it is time to assimilate. Assimilate the best solution(s) while migrating the rest to the chosen solution. As emphasised in Product for Internal Platforms, an early investment of time into migration strategies is essential for such a scheme to sustain.
In platforms designed with experimentation, you will find that innovation continues to thrive at the edges of the platform’s domain while the stable core of the platform is subject to periodic rework or maintenance. The use-cases a platform supports grows in a controlled manner to address an ever-growing percent of the consumers, and does not stagnate after addressing just the median users.
2. Overloaded Use-cases
Although agnostic platform engineering teams might only be catering to very specific median use-cases, the customer teams with specific needs cannot afford to be blocked and they cannot stop delivering their deliverables. These teams sometimes create their own solutions, and in such cases the above strategy of assimilation works wonders. You get a prototype for free on which the team can iterate on. However, this scenario is rarer in cases where it requires specific skills to build such solutions, such as in data platforms. One common pattern in such knowledge-constricted situations is that users find ways to overload the existing solutions with minor tweaks to fit their use-case. Look out for such overloaded use-cases within your platform, for they are excellent guides to unmet needs of the users. You can leverage them to advocate for newer features to explicitly support those use-cases.
3. Listen To Them (Only At The Start!)
As a parting note, I will take a jab at user-interviews again. The above tactics work when you are trying to scale your platform from 1 to N. When taking a platform from 0 to 1, the only solution to creating specifications is to listen to the users. Give them exactly what they want. Listen to their exact demands. A propensity of platform product managers is to rely on this excessively at a much later stage in the product’s lifecycle. User-interviews have their place in evolving products, but the over-reliance on the methodology is a bane to platform product management.
P.S. As I read back the above essay, the heavy influence of Product for Internal Platforms is clear. I would like to say that was the intention: to reassert the ideas in it which resounded with me, while stating a few of my own.
Footnotes
Innovation Loops
18 Apr 2020 •MANAGEMENT CULTURE PRODUCT The purpose of an engineering organization (at the risk of sounding frivolously reductionist) is to build business value. You can grow an organization’s delivered business value over time by: 1
A cumulative side-effect of these approaches is to strengthen innovation loops.
Innovation Loops
Innovation loops are informal, intrapreneurial feedback loops in engineering teams which builds products & features to address user demand & pain. It is innovation which circumvents the software development cycle involving product & market research teams. In mature teams, innovation loops complement & reinforce the existing, evolutionary product development feedback cycle. I call product development evolutionary, in contrast to the more revolutionary (or reactive) trait of innovation loops.
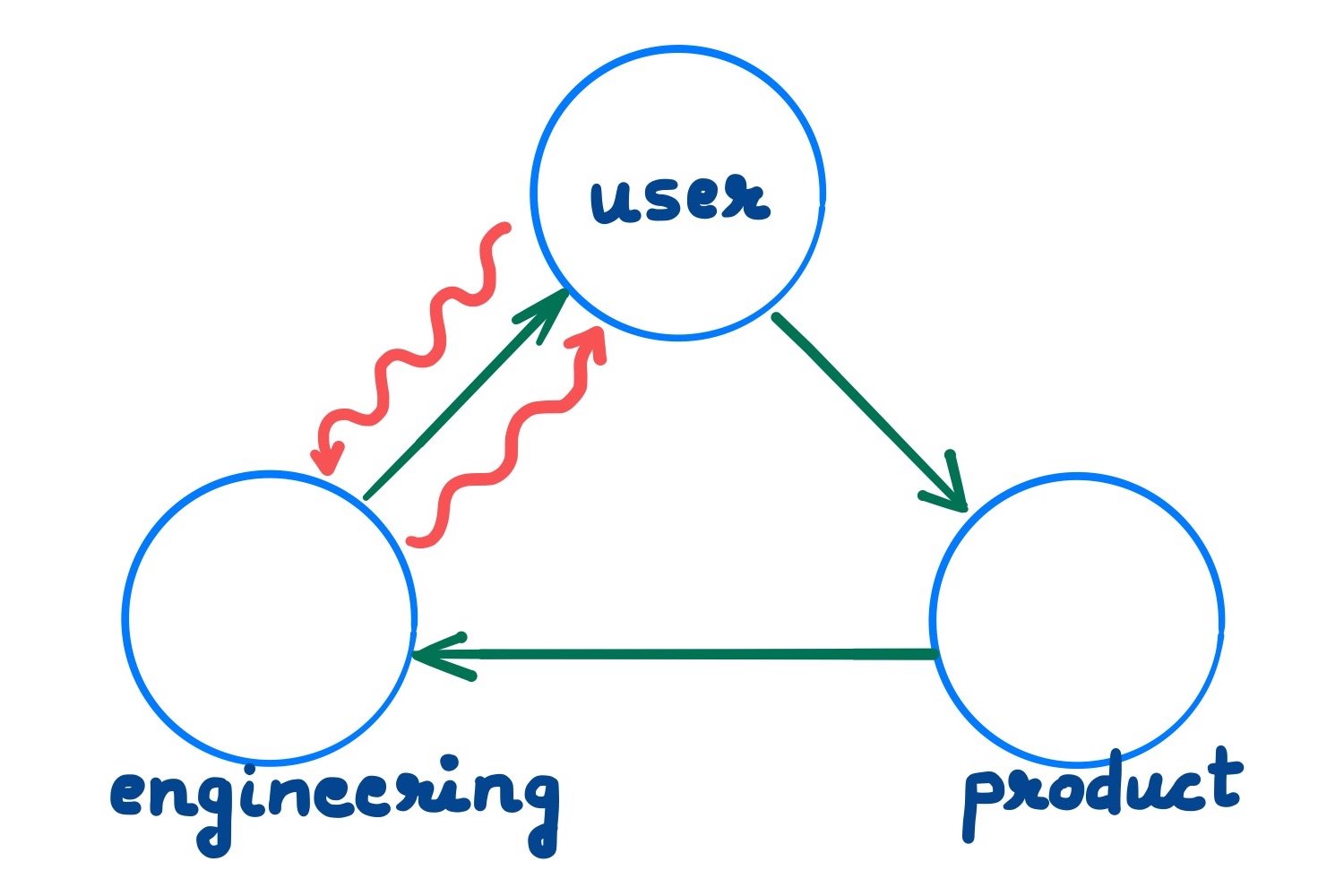
Innovation loops are more prevalent in infrastructure teams than in product-focused teams. This could be partly explained by the availability of direct communication channels to users which infrastructure teams possess, and product-focused teams do not.
.. Read More